Web Scraping Project
In the past, multiple hardware areas had trouble offering enough products to cover the needs of all consumer. From graphic cards, processors and next gen. consoles like the PS5. Since i also wanted to get my hands on one of the PS5s, i did follow the announcements, where and when they might be available again. But after i learned, that the common buyer most likely will not be able to get one, due to the various bots that fetch them right away. I started to learn more and more about the technologies beeing used, simply because i was interested to see, if this could become my next project.
First of all, i "did not want to create a full blown bot", that is able to buy the products in the end, but ... since the different twitter and forum messages, combined with the known news articles have not been sufficient and outdated, i decided to aim for: 'A single information page, that will gather the information from different sources and update itself automatically' So, with that in mind and after making a couple of researches, i ended up with my first idea: Creating a python Web Scraping script, that collects the different information and pushes this information to a cloud persistence.
For this approach i used the most common libraries to get things done (requests, urllib, beautifulsoup...) Google Cloud Functions and Firestore seemed to be an option to trigger and persist the different information, as well as getting familiar with another Cloud provider and his APIs. At the end, i was able to commit my Python script, deal with all Credentials and auth. concepts and push the fetched results to the Firestore storage.
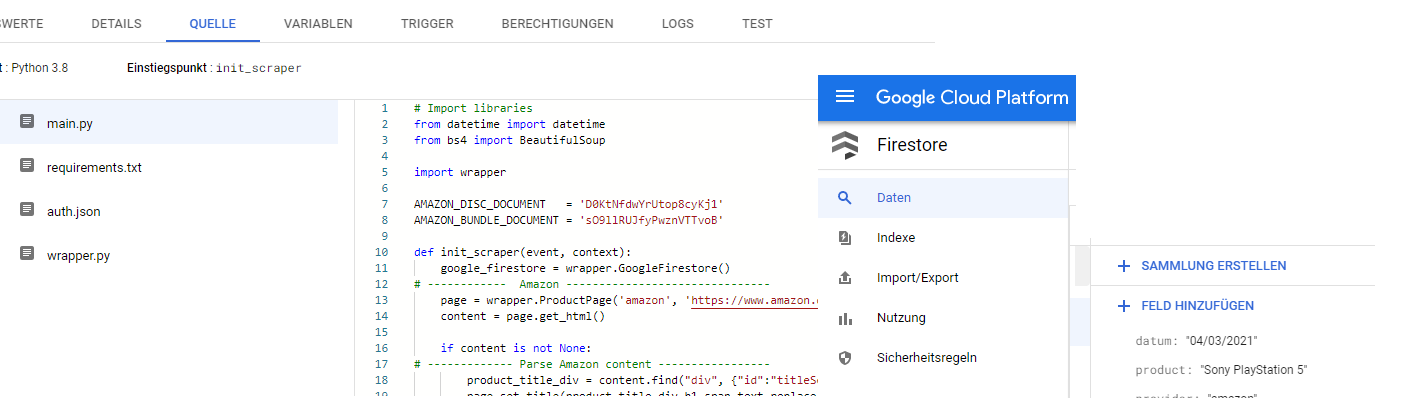
Unfortunately i had to overcome further issues, that could not be covered by this approach. For example the frequency of creating GET requests, to fetch the data. Also, multiple provider do validate HTTP requests, to identify potential, automated bot requests - to be honest... thats exactly what i was trying to do. Besides that, some pages do prefer to do lazy loading - meaning, the actual content will be fetched later by using Javascript functions for example. Due to that, a simple request will not be able to collect the expected content.
Since all of this already took me a couple of days to figure out, i decided to invest a few hours more and redesign my python script, using Selenium instead. Even if this is expected to be used for Testing purposes it can also be used overcome the issues mentioned above. It might be slower, since an actual instance of an browser will be loaded but the actual profit of this, to be able to fetch lazy loaded content for example, was enough to give it a try.
Having a new script in place, that does return the expected content was already a great feeling - but one thing was still open: Executing the script automatically and persist the data. To get this done, i thought "why not use the hardware that is already available to me?" - So i ended up with added the script to my raspberry and triggered it via batch jobs regularly.



